طراحی سیستمهای توزیعشده و معماری مایکروسرویس، در کنار تمام مزایایی که داره، یک چالش جدی هم با خودش میاره: حفظ یکپارچگی دادهها.
یک سیستم ساده و سنتی، معمولا همه چیز رو داخل یک دیتابیس و یک transaction انجام میده. و همه تغییرات یا با هم commit میشن، یا همه با هم rollback میشن و جای نگرانی خاصی از این بابت ندارن.
اما توی سیستمهای توزیعشده، داستان به همین سادگی نیست. خیلی وقتها یک سرویس باید هم دیتابیس خودش رو آپدیت کنه، هم یک پیام یا event رو برای سرویسهای دیگه بفرسته. مثلا Order Service سفارش رو که ذخیره کرد، باید به Payment Service، Inventory Service یا Notification Service هم خبر بده.
روی کاغذ ساده است: سفارش ثبت شد، پس سایر سیستمها رو مطلع میکنیم. اما سوال مهم اینجاست:
اگر سفارش توی دیتابیس ذخیره شد، ولی قبل از ارسال پیام به Kafka یا RabbitMQ، سرویس crash کرد چی میشه؟
یا برعکسش، اگر پیام به broker ارسال بشه، اما transaction داخل دیتابیس، commit نشه چی؟
و بدتر از همه، اگر این اتفاق نیمهشب برای چند دقیقه بیوفته و شما فردا صبح متوجه بشید که دیتابیسِ سفارشات یه چیز میگه و سرویسهای دیگه، یه چیز دیگه، حالا باید دنبال sync کردن، پیدا کردن رکوردهای جاافتاده، replay کردن دستی eventها و کلی دردسر عملیاتی برید.
برای حل این چالش، دو تا الگوی خیلی کاربردی و جاافتاده داریم:
- Transactional Outbox
- Idempotent Inbox
در عمل معمولا این دو تا رو کنار هم به عنوان Outbox/Inbox Pattern میشناسیم.
این دو تا الگو قرار نیست سیستم رو بهطور کامل از بابت exactly-once گارانتی کنن؛ اما کمک میکنن یک طراحی واقعبینانه و قابل اتکا داشته باشیم:
- پیامهای مهم گم نشن.
- پیامهای تکراری باعث انجام چندبارهی کارها، مثل چند بار برداشت از حساب یا چند بار ارسال کالا یا… نشن.
- خطاها قابل مشاهده و قابل جبران باشن.
مسئله اصلی: Dual Write Problem
مشکل از جایی شروع میشه که یک سرویس مجبور میشه دو تا کار رو با هم انجام بده:
- تغییر state داخلی خودش در دیتابیس
- ارسال پیام به یک سیستم بیرونی مثل Message Broker
مثلا برای یک فروشگاه آنلاین:
– Order Service سفارش رو داخل دیتابیس خودش ذخیره میکنه.
– بعد یک event به نام OrderCreated منتشر میکنه.
– Payment Service و Inventory Service با دریافت event وظایف خودشون رو انجام میدن.
مسئله اینه که دیتابیس و Message Broker معمولا داخل یک transaction مشترک نیستند. یعنی نمیتونیم راحت بگیم:
اعمال تغییرات در دیتابیس و publish پیام، یا کامل و توأم با هم انجام میشه یا هیچکدوم انجام نمیشه. همین باعث Dual Write Problem خواهد شد.
سناریوی بروز مشکلات – ۱
شرایطی رو تصور کنین که داده توی دیتابیس ذخیره میشه، اما قبل از ارسال پیام، سرویس crash میکنه.
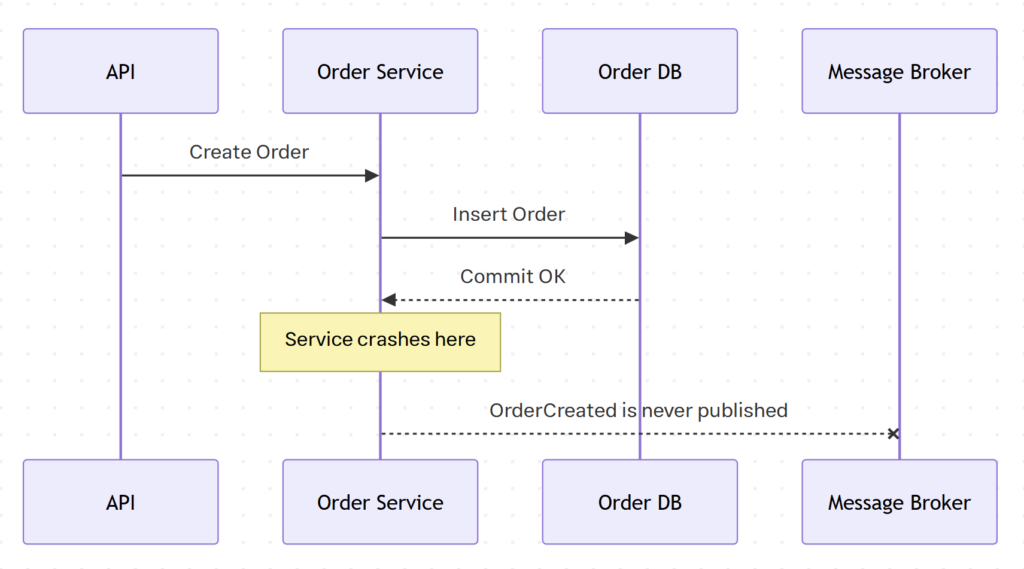
نتیجه؟ سفارش توی دیتابیس سفارشات وجود داره، اما پرداخت، ارسال از انبار یا اعلان خرید موفق به کاربر انجام نمیشه، چون پیام به دست سرویسهای مرتبط نرسیده.
از نگاه Order Service همه چیز درسته ولی از نگاه بقیه سیستمها، انگار اصلا چنین سفارشی وجود نداره.
سناریوی بروز مشکلات – ۲
پیام به broker ارسال میشه، اما توی دیتابیس مقصد، اعمال نمیشه.
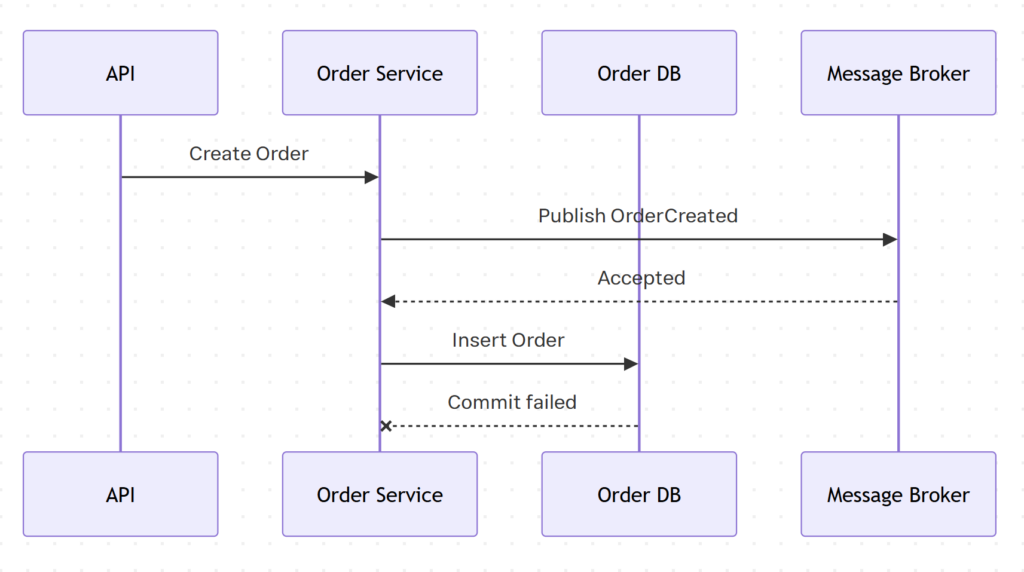
اینجا برعکس حالت قبل اتفاق میافته، یعنی سرویس پرداخت یا پردازش انبار، پیام مربوط به اطلاعات سفارش رو دریافت میکنن، سفارشی که توی دیتابیس مبدأ «قرار بوده» ثبت بشه؛ پیام ارسال شده، ولی ثبت در دیتابیس مبدأ با مشکل روبرو میشه و rollback میشه.
این شرایطیه که خیلی از سیستمهای event-driven توی محیط production ازش ضربه میخورن. نه به خاطر اینکه Kafka یا RabbitMQ کارشون رو درست انجام نمیدن، بلکه به خاطر اینکه مرز transaction درست طراحی نشده.
الگوی Outbox
Outbox Pattern برای حل بخش اول مشکل بهکار میاد؛ یعنی اینکه اگر تغییر توی دیتابیس مبدأ اعمال شد، اطمینان پیدا کنیم که پیام مربوط به اون تغییر گم نمیشه؛ و حتی اگر بروکر یا… دچار مشکل بشه، ما پیام رو ذیل همون تراکنشی که تغییر اصلی رو ذخیره کرده، در جایی ذخیره کردیم.
ایده خیلی ساده است:
– پیام رو مستقیم به broker نمیفرستیم.
– اول داخل همون دیتابیس و همون transaction ذخیره میکنیم.
– بعدا یک process جدا میاد و پیام رو میخونه و publish میکنه.
– اگر هم دچار وقفه و مشکل شدیم، معلومه چه پیامی توی صف ارسال (صف خروج) بوده و بعد از برگشتن به حالت عادی، میخونیم و ارسالش میکنیم.
یعنی به جای:
۱: Insert Order
۲: Publish OrderCreated
این روال رو دنبال کنیم:
۱: Begin Transaction
۲: Insert Order
۳: Insert Outbox Message
۴: Commit
بعد یه background worker یا message relay میاد جدول Outbox رو میخونه و پیامهای publish نشده رو به broker میفرسته.
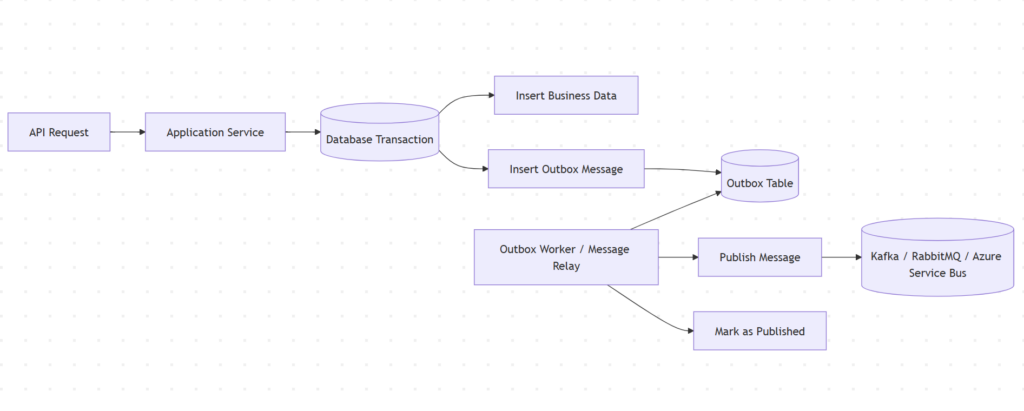
مزیت اصلی این الگو اینه که business data و outbox message طی یک transaction محلی ذخیره میشن. بنابراین اگر سفارش ثبت شد، event مربوط بهش هم توی دیتابیس ثبت شده. شاید هنوز publish نشده باشد، ولی گم نمیشه.
نکته: Outbox تضمین نمیکنه پیام همون لحظه به broker برسه، بلکه تضمین میکنه اگر transaction اصلی موفق شد، پیام توی دیتابیس باقی مونده و سیستم میتونه بعدا برای publish کردنش اقدام کنه.
اینجا یه سوءبرداشت رایج وجود داره؛ Outbox معمولا ما رو به سمت at-least-once publishing میبره، ولی نه exactly-once delivery.
فرض کنین Outbox Worker پیام رو از جدول Outbox میخونه، بعد با موفقیت به broker میفرسته، اما درست قبل از اینکه رکورد Outbox رو به وضعیت Published تغییر بده، یه مشکلی برای اپلیکیشن پیش میاد.
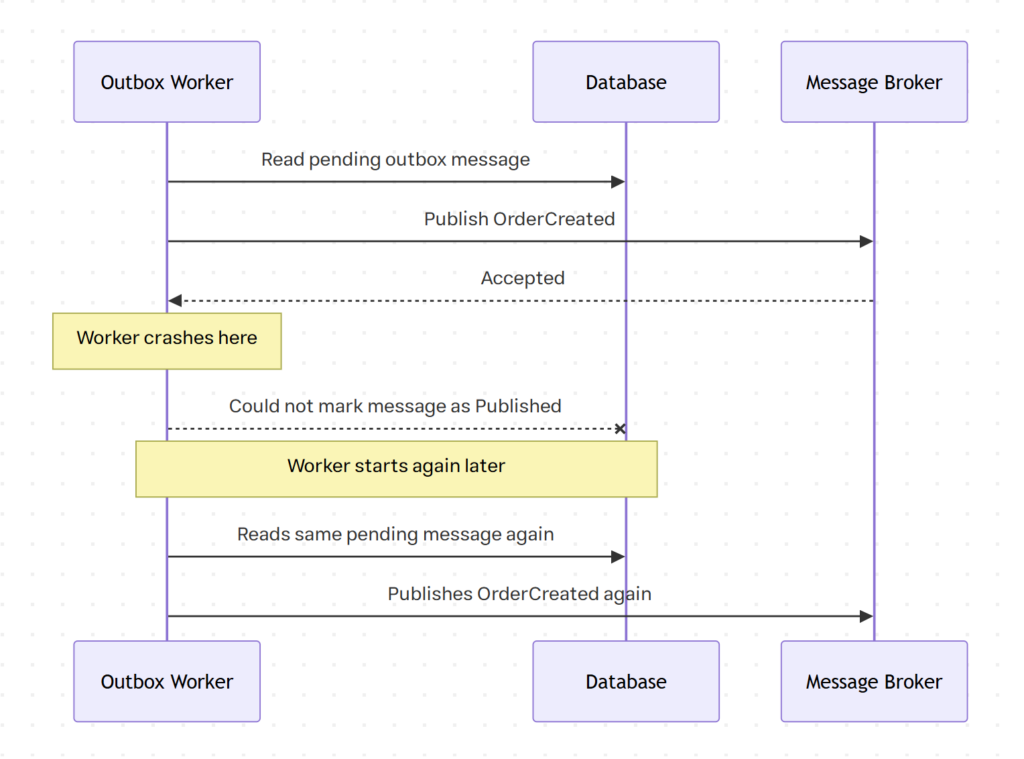
توی این شرایط، همون پیام ممکنه دوباره publish بشه! پس Outbox جلوی گم شدن پیام رو میگیره، ولی به تنهایی جلوی duplicate شدن پیام رو نمیگیره. همینه که Inbox Pattern و idempotency مهم میشن.
الگوی Inbox
Inbox Pattern معمولا سمت consumer استفاده میشه؛ هدفش هم اینه که اگر یک پیام چند بار به consumer برسه، اثرش چند بار اعمال نشه. مثلا اگر پیام OrderCreated دوبار رسید، Payment Service نباید دوبار از کیف پول کاربر پول کم کنه.
یا اگه پیام EmployeeTerminated دوبار رسید، Access Management نباید دوبار همون عملیات رو اجرا کنه و رفتارهای عجیب ازش بروز بده.
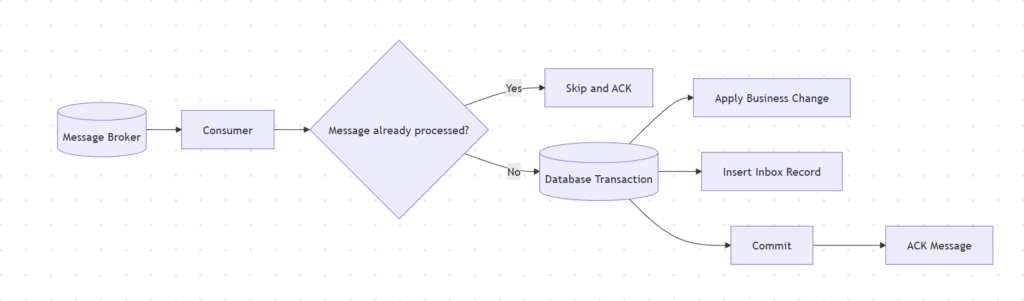
ایده Inbox ساده است:
– هر پیام باید یک شناسه یکتا داشته باشد.
– Consumer قبل از پردازش پیام، بررسی میکنه که قبلا این پیام پردازش شده یا نه.
– اگه قبلا پردازش شده، پیام رو skip میکنه.
– ولی اگه جدیده، business operation رو انجام میده و شناسه پیام رو توی جدول Inbox ثبت میکنه.
نکته مهم اینه که اجرای business operation و ثبت Inbox record باید طی یک transaction انجام بشن.
اگر هم business operation انجام بشه؛ ولی Inbox record ثبت نشه، پیام بعدا دوباره پردازش خواه شد. و اگر هم Inbox record ثبت بشه ولی business operation انجام نشه، پیامهای بعدی به اشتباه skip میشن. پس این دو تا باید با هم انجام بشن.
تصدیق دریافت و پردازش پیام کجا باید انجام بشه؟
در طراحی consumer، طراحی مکانیزم و روش تصدیق دریافت و پردازش پیام خیلی مهمه و ترتیب درست این فرایند عمومای این شکلیه:
– پیام از broker دریافت میشه.
– Consumer دیتابیس خودش رو چک میکنه تا اگه پیام جدید بود، business operation رو انجام بده.
– Inbox record رو ثبت میکنه.
– Transaction دیتابیس رو commit میکنه.
– بعد از commit، پیام رو تایید میکنه.
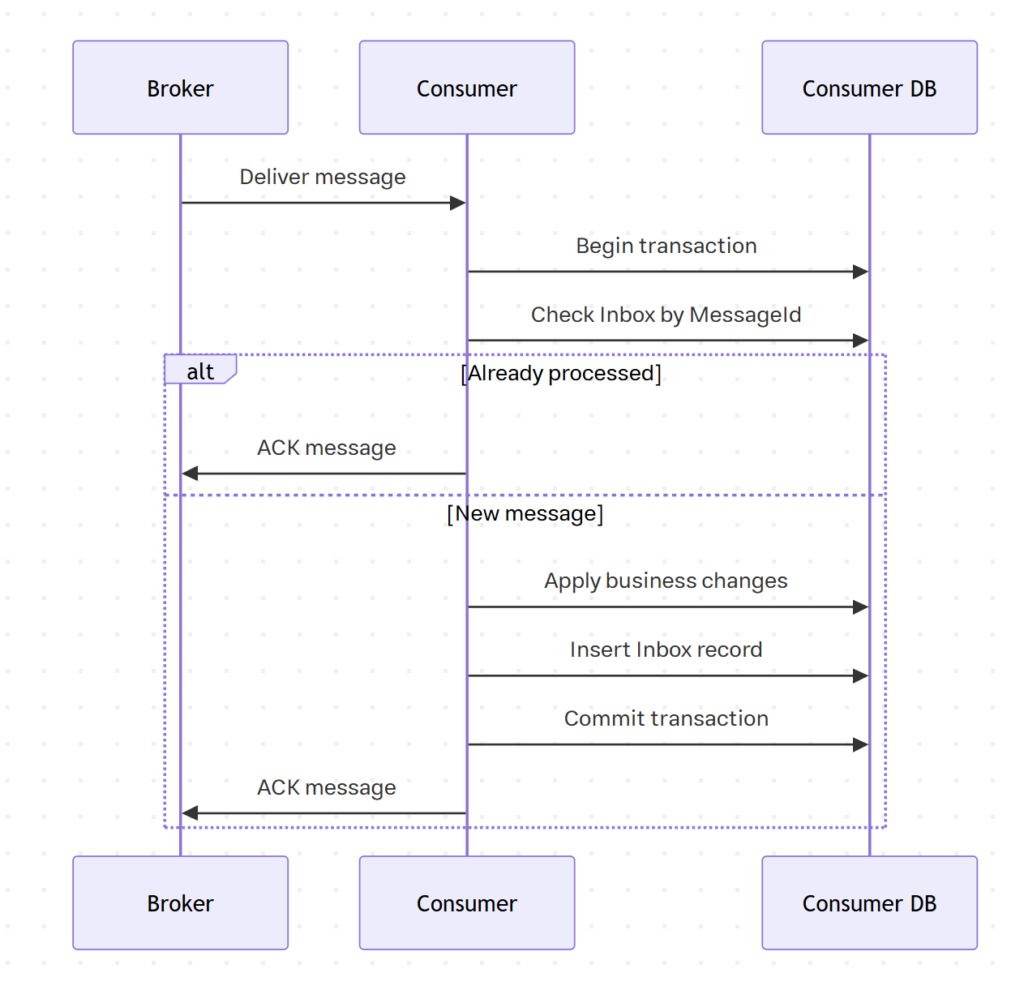
حالا اگر قبل از commit، پیام را تایید کنیم و بعد دیتابیس به هر دلیلی با مشکل روبرو بشه، پیام از نگاه broker مصرف شده، ولی اثرش توی دیتابیس ثبت نشده.
ولی اگه تراکنش دیتابیس موفق باشه ولی قبل از تایید پیام، consumer دچار مشکل بشه، broker ممکنه همون پیام رو دوباره تحویل بده. توی چنین شرایطی، Inbox جلوی پردازش دوباره رو میگیره. این طراحی واقعبینانه است و با در نظر گرفتن حالتهای مختلف مشکلات، برای سیستمهای توزیعشده مناسبه.
مثال: سیستم فروشگاهی (سرویسهای سفارش و پرداخت)
فرض کنیم کاربر یک سفارش ثبت میکنه. Order Service باید سفارش رو ذخیره کنه و ایونت ثبت سفارش رو منتشر کنه تا Payment Service بتونه فرایند پرداخت رو دنبال کنه.
ساختار ساده جدول Outbox
CREATE TABLE OutboxMessages (
Id UNIQUEIDENTIFIER NOT NULL PRIMARY KEY,
AggregateType NVARCHAR(100) NOT NULL,
AggregateId NVARCHAR(100) NOT NULL,
EventType NVARCHAR(200) NOT NULL,
EventVersion INT NOT NULL,
Payload NVARCHAR(MAX) NOT NULL,
Status NVARCHAR(50) NOT NULL,
RetryCount INT NOT NULL DEFAULT 0,
CreatedAt DATETIME2 NOT NULL,
PublishedAt DATETIME2 NULL,
LastError NVARCHAR(MAX) NULL
);برای محیط production معمولا فیلدهای بیشتری لازم داریم، مثل:
CorrelationId
CausationId
TraceId
NextRetryAt
LockedBy
LockedUntil
OccurredAtثبت سفارش و Outbox طی یک تراکنش:
BEGIN TRANSACTION;
INSERT INTO Orders (id, user_id, total_amount, status)
VALUES ('order_999', 'user_123', 150, 'Pending');
INSERT INTO OutboxMessages (
Id,
AggregateType,
AggregateId,
EventType,
EventVersion,
Payload,
Status,
CreatedAt
)
VALUES (
'event_001',
'Order',
'order_999',
'OrderCreated',
1,
'{"orderId":"order_999","userId":"user_123","amount":150}',
'Pending',
SYSUTCDATETIME()
);
COMMIT;اگر تراکنش موفق بشه، هم سفارش ثبت شده، هم ایونت مربوط بهش داخل Outbox ذخیره شده. حالا پیام در دسترس Outbox Worker است تا بعدا publish بشه.
ساختار ساده جدول Inbox
در سمت Payment Service، باید مطمئن بشیم که پیام event_001 فقط یک بار پردازش و اعمال میشه.
CREATE TABLE InboxMessages (
MessageId UNIQUEIDENTIFIER NOT NULL,
ConsumerName NVARCHAR(200) NOT NULL,
ProcessedAt DATETIME2 NOT NULL,
PRIMARY KEY (MessageId, ConsumerName)
);چرا ConsumerName؟ چون گاهی یک پیام توسط چندین consumer یا handler مختلف پردازش میشه. پس unique بودن فقط بر اساس MessageId کافی نخواهد بود. ترکیب MessageId و ConsumerName کنترل دقیقتری بهمون میده (خطایابی و مدیریت، سادهتر خواهد شد).
پردازش پیام در Payment Service
BEGIN TRANSACTION;
INSERT INTO InboxMessages (MessageId, ConsumerName, ProcessedAt)
VALUES ('event_001', 'PaymentService', SYSUTCDATETIME());
UPDATE UserWallets
SET balance = balance - 150
WHERE user_id = 'user_123'
AND balance >= 150;
COMMIT;البته برای محصول واقعی باید خطای duplicate key رو هم مدیریت کنیم. و اگر insert داخل Inbox به خاطر primary key شکست بخوره، یعنی پیام قبلا پردازش شده و باید بیخیالش شیم.
یک نکته دیگه هم اینه که برای عملیات مالی، فقط Inbox کافی نیست. خود operation هم باید تا جای ممکن idempotent طراحی بشه. مثلا بهتره payment یا transaction مالی یک شناسه business مستقل داشته باشد تا حتی اگه از مسیر دیگهای هم دوباره درخواست شد، دوبار پول کم نشه.
بررسی جزئیتر مفهوم Idempotency
Idempotency یعنی اگر یک عملیات چند بار اجرا شد، نتیجه نهایی مثل یک بار اجرا شدنش باشه. مثلا این معمولا idempotent است:
PUT /users/123/status/activeاگر چند بار هم اجرا بشه، نهایتا کاربر active است. اما این خطرناکه:
POST /payments/captureچون اگر چند بار اجرا بشه، ممکنه چند بار پول گرفته بشه. توی سیستمهای event-driven باید consumerها رو طوری طراحی کنیم که پیام تکراری باعث side effect تکراری نشه.
روشهای رایج:
– استفاده از Inbox table
– استفاده از MessageId یکتا
– استفاده از business key مثل OrderId یا PaymentId
– استفاده از unique constraint
– طراحی operation به شکل state transition
– بررسی وضعیت فعلی قبل از اعمال تغییر
مثلا:
– اگر صورتحساب برای این سفارش قبلا ساخته شده، صورتحساب جدید براش نساز.
– اگر پرداخت قبلا انجام شده، دوباره انجامش نده.
– اگر درخواست مرخصی کارمند قبلا sync شده، دوباره sync نکن.
طراحی بهتر پیامها
یکی از رایجترین اشتباهات اینه که کل entity داخلی رو serialize کنیم و به عنوان ایونت بفرستیم. این کار، consumerها رو به مدل داخلی سرویس producer وابسته میکنه.
مثلا این طراحی خوبی نیست:
{
"employee": {
"id": 123,
"firstName": "Amin",
"lastName": "Mesbahi",
"salary": 100000,
"address": "...",
"managerNotes": "..."
}
}بهتره تا integration event کوچیک، مشخص، versioned و contract-oriented باشه:
{
"messageId": "event_001",
"type": "OrderCreated",
"version": 1,
"occurredAt": "2026-06-14T10:00:00Z",
"correlationId": "corr_123",
"payload": {
"orderId": "order_999",
"userId": "user_123",
"amount": 150
}
}هر event بهتره version داشته باشه چون شاید ساختار event امروز، شش ماه دیگه تغییر کنه. اگر بدون versioning فیلدی رو حذف کنیم، یا نوع یک فیلد رو تغییر بدیم یا مفهوم و کاربرد کسبوکاری یک فیلد رو عوض کنیم، و با چنین تغییراتی ممکنه consumerهای دیگه دچار مشکل بشن.
تفاوت Domain Event و Integration Event
این هم یکی از جاهاییه که معمولا قاطی میشه.
Domain Event چیزیه که داخل مرز domain شما اتفاق افتاده. ممکنه غنیتر باشه و به مدل داخلی شما نزدیکتر.
Integration Event چیزیه که قراره بیرون از سرویس شما مصرف بشه. پس باید پایدارتر، کوچکتر، امنتر و مناسب contract بین سرویسها باشه.
مثلا داخل Order Service ممکنه OrderPlacedDomainEvent داشته باشیم؛ اما چیزی که بیرون منتشر میکنیم میتونه OrderCreatedIntegrationEvent باشه. لازم نیست هر چیزی که داخل domain اتفاق افتاده، همونطور که هست، و با همون جزئیات به بیرون publish بشه.
روشهای پیادهسازی Outbox Publisher
برای خوندن پیامها از جدول Outbox و انتقالشون به broker، معمولا دو روش اصلی داریم.
روش اول: Polling Publisher یعنی یک background worker هر چند ثانیه یا چند میلیثانیه یک بار جدول Outbox را برای رکوردهای Pending چک میکنه.

مزیتهاش:
– ساده است.
– پیادهسازیاش راحته.
– برای خیلی از سیستمهای کوچک و متوسط کافیه.
– وابستگی زیرساختی کمتری داره.
چالشها:
– ممکنه تاخیر اضافه ایجاد کنه.
– اگه درست طراحی نشه به دیتابیس فشار مضاعف میاره.
– نیاز به locking، retry و backoff داره.
– در multi-instance deployment باید مراقب باشیم چند worker یک پیام رو همزمان برندارن.
برای جلوگیری از پردازش همزمان، بسته به نوع دیتابیس میشه از روشهایی مثل SELECT FOR UPDATE SKIP LOCKED، فیلدهای LockedBy و LockedUntil، یا مکانیزمهای locking استفاده کرد.
روش دوم: Transaction Log Tailing یا CDC، توی این روش به جای اینکه worker مدام جدول رو poll کنه، تغییرات از روی transaction log دیتابیس خونده میشن. مثلا WAL در PostgreSQL یا Binlog در MySQL.
ابزارهایی مثل Debezium هم میتونن تغییرات جدول Outbox رو بخونن و به Kafka منتقل کنن.
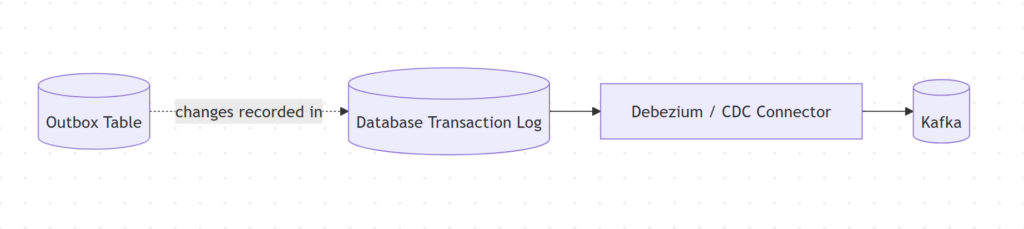
مزیتها:
– برای throughput بالا مناسبتره.
– نزدیک به real-time است.
– فشار مستقیم polling روی دیتابیس کمتر میشه.
چالشها:
– پیچیدگی عملیاتی بیشتری داره.
– نیاز به زیرساخت و مانیتورینگ جدیتره.
– debug کردنش برای تیمهای کوچک سختتره.
– معمولا بیشتر با Kafka و Kafka Connect معنی پیدا میکنه.
پس اینکه بگیم CDC همیشه بهترین گزینه است، دقیق نیست. برای بعضی سیستمها عالیه، اما برای خیلی از تیمها، یک Polling Publisher درست و تمیز کاملا کافیه.
ابزارها و فریمورکهای رایج برای پیادهسازی inbox/outbox
اکوسیستم NET. چندین گزینه شناختهشده داره.
MassTransit یکی از گزینههای محبوب برای messaging است (یا شایدم بود! چون بعد از تغییر رویکردش و تبدیل شدن به مدل تجاری و قیمت بالای لایسنس، برخی شرکتهای کوچیک رو وادار به بررسی مجدد کرد) و با transportهایی مثل RabbitMQ، Azure Service Bus و Amazon SQS کار میکنه. برای Outbox هم از امکانات درونی خوبی برخورداره که راهاندازیاش هم ساده و سرراسته. و برای تیمهایی هم که نمیخوان همه چیز رو از صفر بسازن، گزینه قابل بررسی میتونه باشه.
CAP هم برای NET. امکانات event bus و transactional outbox رو محیا میکنه و برای سناریوهای سادهتر میتونه انتخاب سبکتر و سرراستی باشه. خصوصا که رایگان و کدبازه و لایسنس MIT داره.
NServiceBus از نظر enterprise messaging به تجربه من، پختهترینه؛Outbox Pattern رو خیلی خوب پشتیبانی میکنه، اما هزینه و licensing اش هم به همین نسبت تُنده!
Wolverine هم توی اکوسیستم NET. برای messaging، command handling و durable messaging قابل بررسیه. لایسنس MIT هم داره.
برای Java، ابزارهایی مثل Eventuate Tram، Axon Framework، Spring Cloud Stream و Spring Integration بسته به معماری و نیاز تیم میتوانند بخشی از راهحل باشن.
در سطح زیرساخت هم باید حواسمون باشه که خود Kafka یا RabbitMQ به تنهایی Dual Write Problem دیتابیس رو حل نمیکنن. هنوز به Outbox یا یه طراحی معادل نیاز دارین.
Poison Message، Retry و Dead Letter
همه خطاها موقتی نیستن! گاهی broker برای چند ثانیه در دسترس نیست. این یک خطای transient است و retry بعد از مواجهه باهاش منطقیه.
اما گاهی پیام از اساس مشکل داره. مثلا schema آن ایراد داره؛ payload ناقصه، یا consumer به خاطر یک خطای کسبوکاری (مثل تاریخ استخدام بعد از تاریخ استعفا) همیشه خطا میده. به این نوع پیامها معمولا poison message میگیم.
برای این حالتها باید آمادگی داشته باشیم:
– RetryCount
– NextRetryAt
– Exponential Backoff
– Max Retry
– Failed State
– Dead Letter Queue یا به اختصار: DLQ
– Manual Retry
اگر یک پیام ۱۰۰۰ بار fail بشه و ما همچنان هر چند ثانیه دوباره تلاش کنیم، فقط داریم سیستم را مشغول میکنیم و مشکل رو انکار! پس بهتره تا بعد از تعداد مشخصی retry، پیام وارد وضعیت Failed یا DLQ بشه و alert بدیم تا بررسی انسانی انجام بشه.
Observability و Monitoring
Outbox بدون monitoring خطرناکه! چون ممکنه سیستم ظاهرا بالا باشه، APIها هم جواب بدن، اما پیامها در جدول Outbox گیر کرده باشن و هیچکس متوجه نشه. چند متریک مهم:
Outbox pending message count
Oldest unpublished message age
Outbox publish failure count
Outbox retry count
Failed message count
Average publish latency
Inbox duplicate count
Consumer processing latency
Dead-letter countنمونههایی از alert های مفید:
– اگر تعداد پیامهای Pending از یک حدی بیشتر شد.
– اگر قدیمیترین پیام Pending بیشتر از چند دقیقه یا چند ساعت باقی موند.
– اگر تعداد Failed message زیاد شد.
– اگر duplicate rate ناگهان بالا رفت.
برای trace کردن جریان پیامها هم بهتره CorrelationId، CausationId و TraceId رو با پیام منتقل کنیم. وگرنه در محیط production، پیدا کردن اینکه یک درخواست از کجا شروع شده و به دست کدوم سرویسها رسیده، سخت و زمانبر میشه.
Ordering پیامها
ترتیب پیامها توی برخی سناریوها مهم نیست؛ ولی وقتی مهم باشه، خیلی مهمه! مثلا برای یک سفارش ممکنه این eventها رو داشته باشیم:
OrderCreated
OrderPaid
OrderShipped
OrderCancelledاگر consumer اینها رو با ترتیب اشتباه ببینه، state اشتباه میسازه و همین میتونه باعث بشه توی یک state اشتباه گیر کنه و متوقف شه چون مثلا در حالیکه اطلاعات پرداخت براشت وجود نداره رسیده به وضعیت ارسال. برای همین هم کنترل ordering چند روش رایج داره:
– استفاده از AggregateId به عنوان partition key در Kafka
– داشتن sequence number یا version در event
– پردازش ترتیبی در سطح یک aggregate
– نادیده گرفتن eventهای قدیمیتر
– طراحی consumer بر اساس reconciliation
اما نباید بیدلیل دنبال ordering سراسری در کل سیستم بریم. ordering کامل، در سطح کل سیستم، معمولا پیچیده، گرون و کندکننده است. در خیلی از سناریوها ordering در سطح aggregate کافیه. مثلا در سطح یک OrderId یا یک EmployeeId.
پاکسازی دادهها
جداول Outbox و Inbox به مرور بزرگ میشن؛ و بسته به هر سیستمی میتونه بین چند ساعت تا چند ماه این «بزرگ شدن» طول بکشه. اگر retention policy نداشته باشیم، همین جدولهای کمکی میتونن روی performance دیتابیس اثر منفی بگذارن یا بهصورت کلیتر، مشکل یا هزینه ذخیرهسازی رو بهوجود بیارن.
بسته به نیاز audit و compliance، میتونیم رکوردهای قدیمی رو حذف یا آرشیو کنیم.
مثلا:
– پیامهای Published قدیمیتر از ۳۰ روز حذف یا آرشیو بشن.
– Inbox records قدیمیتر از ۹۰ روز حذف یا آرشیو بشن.
– Failed messages تا زمان بررسی نگهداری بشن.
البته عددهایی مثل ۲۴ ساعت، ۳۰ روز یا ۹۰ روز نسخه عمومی نیستند. باید بر اساس نیاز business، امکان replay، الزامات audit و حجم سیستم تصمیم گرفت.
Outbox با Event Sourcing چه فرقی داره؟
گاهی Outbox با Event Sourcing اشتباه گرفته میشه. توی Outbox، دیتابیس عملیاتی هنوز منبع اصلی state است. مثلا جدول Orders یا Payments. جدول Outbox فقط کمک میکند integration eventها قابل اعتماد publish بشن.
اما توی Event Sourcing، خود eventها منبع اصلی حقایق هستن و state فعلی از replay کردن eventها ساخته میشه.
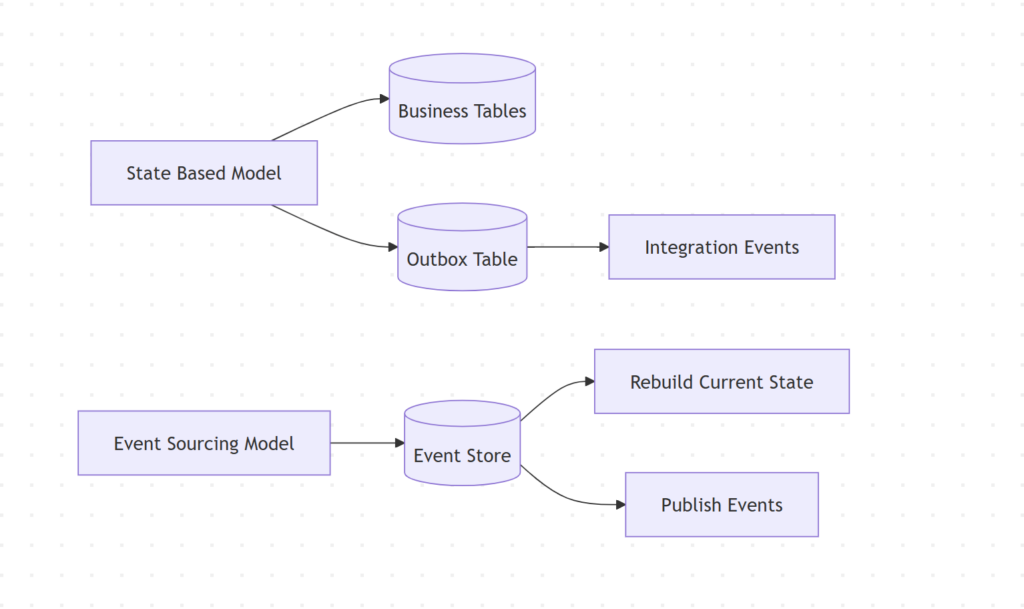
پس هر Outbox ای Event Sourcing نیست. Outbox یک الگوی reliability برای انتشار پیامه. Event Sourcing یک مدل متفاوت برای ذخیره state سیستم.
Outbox و Inbox چه نسبتی با Saga دارن؟
Saga برای مدیریت یک فرایند چندمرحلهای بین چند سرویس استفاده میشه.
مثلا:
Create Order
Reserve Inventory
Capture Payment
Confirm Order
Send NotificationOutbox کمک میکنه eventهای هر مرحله گم نشن. Inbox کمک میکنه تا هر سرویس پیامهای تکراری رو امن پردازش کنه.
Saga هم کل فرایند business رو مدیریت میکنه، چه با choreography و چه با orchestration.
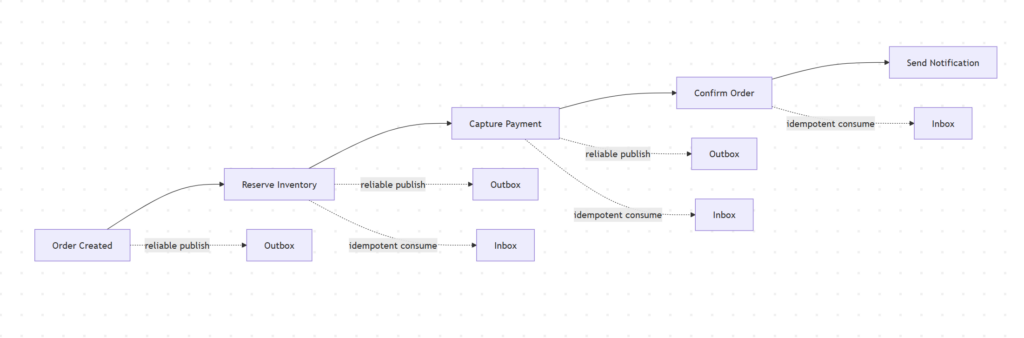
به زبون ساده:
– Outbox: پیام را گم نکن.
– Inbox: پیام تکراری را دوباره اثر نده.
– Saga: کل فرایند چندمرحلهای را مدیریت کن.
چه زمانی واقعا به Inbox و Outbox نیاز داریم؟
اگر event شما فقط برای telemetry یا log غیرحیاتیه، شاید Outbox ارزش پیچیدگی اضافه رو نداشته باشه.
اما اگر event باعث یک تصمیم یا side effect مهم توی سیستم میشه، بهتره تا موضوع رو جدی بگیرید. مثالهای رایجی که Outbox معمولا براشون ارزشمند به شمار میاد:
- OrderCreated
- PaymentCaptured
- InvoiceGenerated ShipmentRequested EmployeeTerminated
- LeaveSubmitted
- UserRegistered
- ContractSigned
و مثالهای رایجی که Inbox یا idempotency براشون کاربردی و مهمه:
– کم کردن موجودی
– برداشت از کیف پول
– ساخت invoice
– ارسال notification حساس
– تغییر وضعیت کارمند
– قطع یا تغییر سطح دسترسی
– ثبت payroll adjustment
قاعده ساده اینه: اگر گم شدن پیام برای business مهمه، Outbox لازمه. اگر پردازش تکراری پیام خطرناکه، Inbox یا مکانیزم idempotency لازم میشه.
جمعبندی
Inbox و Outbox Pattern جزو الگوهایی هستن که شاید در پروژههای کوچیک اولش کمی اضافه به نظر برسن، اما در سیستمهای واقعی خیلی زود ضرورتشون مشخص میشه.
وقتی فقط یک دیتابیس و یک application نداریم، وقتی چند سرویس با هم حرف میزنن، وقتی پیامها باعث تصمیمهای کسبوکاری میشن، دیگه نمیشه فقط امیدوار بود که همه چیز درست کار میکنه.
امین جان،
سلام،
چقدررررر حسن تصادف داشت برای من،
زمان انتشار این مطلب،
با گفتگویی که ساعتی قبلش با همکارم داشتم ،
در مورد چالش تقدم و تأخر انتشار ایونت بین سه چهار سرویس مختلف، که امروز برای چندم بهش برخوردیم.
از شما متشکرم بابت نشر این محتوای خوب، ساده، دقیق و مفید
بسیار مفید بود
ممنونم
بسیار مطلب اموزنده ای بود ممنون ازتون بابتش