
اصلا GraphQL چیه؟
به زبان ساده، GraphQL مکانیزمیه تا بتونیم با یک استاندارد مشخص، کوئریمون رو به «یک» API ارسال کنیم و دادهها رو دریافت. یعنی بابت هر دادهای که نیاز داریم دریافت کنیم سراغ یک REST API جداگانه نریم. بلکه فارغ از اینکه دادههامون یک جا هستن یا از منابع مختلفی تأمین میشن، صرفا میگیم «چی میخوایم با چه شرایطی» (مثلا تمام دانشآموزهای ۱۰ تا ۱۵ ساله که معدل بین ۱۷ تا ۱۹ داشتن) و بعد این کوئری رو ارسال میکنیم و پاسخمون رو میگیریم. و این عملا یک لایهی واسط روی دادهها (متمرکز یا حتی توزیعشده + یک منبع داده یا چند منبع داده) به ما میده که میتونه نیازهای توسعهدهندههای خودمون یا مشتریانمون رو برآورده کنه.
اینکه کاربر صرفا میگه چی میخوام رو اصطلاحا “declarative data fetching” میگیم.
پیدایشش هم به سال ۲۰۱۲ برمیگرده که Lee Byron, Nick Schrock و Dan Schafer برای حل گرفتن دیتا برای اپلیکیشنهای موبایل، توی فیسبوک دست به خلق GraphQL زدند، و بعدتر در سال ۲۰۱۵ بهصورت کدباز عرضهاش کردند. به صورت سنتی مشکلات زیر در رابطه با REST API وجود داشت که منجر به پیدایش GraphQL شد. مثل:
- مشکل Over-fetching (دریافت دادههایی بیش از دیتای مورد نیاز، مثلا: ما ۳ تا فیلد رو نیاز داریم ولی API ما ۱۰ تا فیلد رو برمیگردونه، که این توی مقیاس بزرگ میتونه منجر به هدررفت منابع پردازشی و ارتباطی بشه)
- مشکل Under-fetching (دریافت دادههایی کمتر از اونچه نیاز داریم که منجر به درخواستهای متعدد برای تکمیل دادههای مورد نیاز است، مثلا: چند API رو صدا کنیم و دادههای همه رو با هم ترکیب کنیم تا اونچه نیاز داریم رو از دلشون در بیاریم)
- انعطافپذیری کم endpointها نسبت به نیازهای سمت front
حالا چه مشکلاتی رو قراره برطرف کنه؟
- واکشی بهاندازه و دقیق دادهها (هر دیتایی با هر شرط و فیلتری و هر ساختاری رو بتونیم واکشی کنیم)
- انعطاف پذیری API از منظر طراحی (پشتیبانی از طیف وسیعی از امکانات)
- یک endpoint برای چندین منبع داده (در مقابل شرایطی که برای هر سرویس یا منبع داده، یک گروه REST API ارائه میکنیم)
- ساختار strong typing
مناسب برای…
- نرمافزارهای پیچیده و دادهمحور (دیتامدلهای پیچیده، منابع داده متعدد «با تعریف استاندارد!! نه دلخواه مدیرعامل شرکت که حتی نرمافزار دفترتلفن رو توی لینکدینش پیچیدهترین نرمافزار جهان معرفی میکنه 😂😉)
- معماری میکروسرویس (خصوصا توی سازمانهای بزرگ با دامینهای کاری متعدد)
- نرمافزارهای موبایل و فرانتاند با نیازهای دادهایِ پویا (دست فرانتاند دولوپر رو باز میگذاره تا هر چی خواست سریع توسعه بده)
محدودیتهاش:
- افزایش پیچیدگی برای APIهای ساده (دقت کنیم کجا مناسبه برای استفاده از GraphQL)
- سربار پرادزشی بالقوه برای کوئریهای پیچیده (نمیشه روی همه کوئریها، همه حالتها ایندکس گذاشت، کاربر میتونه یه کوئری بفرسته که باعث کُندی سیستم بشه!)
- راهاندازی اولیه نسبتا سنگین و زمانبری داره
- منحنی یادگیری برای تیمهایی که REST بلد هستن و دیدگاه REST API Design دارن کمی زمانبر و نیاز به تغییر دیدگاه داره
چالشهای بالقوه:
- مدیریت عمق و پیچیدگی کوئریها نیاز به تحقیق و دقت زیادی داره
- مکانیسم caching پیچیدهتر از REST است (گاهی خیلی پیچیدهتر)
- مستعد مصرف منابع پردازشی زیاد
- ملاحظات امنیتی (پیچیدگی کوئریها، محدودیت نرخ درخواست، امنیت در سطح داده و خصوصا لایههای دوم به بعد..)
اگر موافقید با یه مثال شروع کنیم:
- نکته: سرویسهای GraphQL رایگان و آنلاینی وجود دارند که من برای دسترسی سریعتر شما به مثالها با اونها پیش میرم. با یک سرویس ساده که اطلاعات کشورها رو در قالب GraphQL ارائه میده پیش میریم. تصویر زیر با استفاده از نرمافزار postman است.
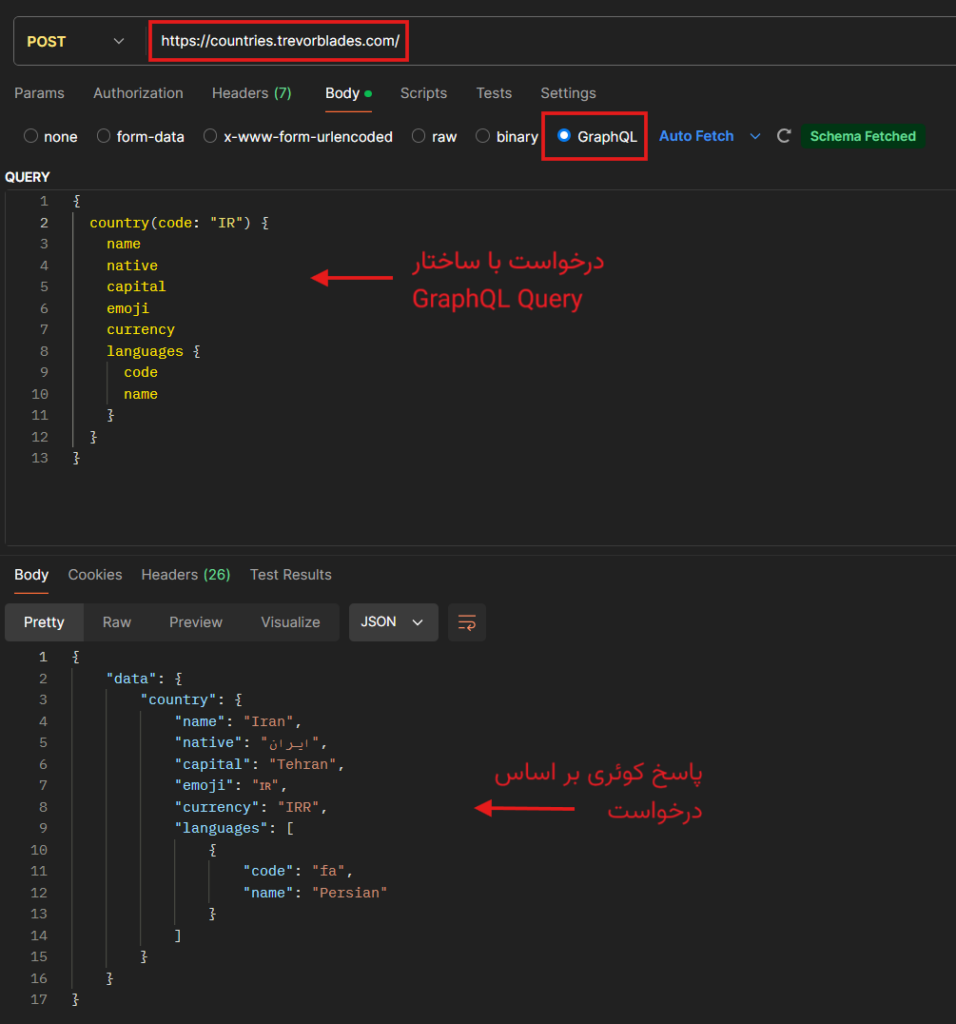
عملا ما با یک ساختار استاندارد، فیلدها، فیلترها و… رو مشخص میکنیم، و سرور به ما پاسخ رو برمیگردونه، اینجا اگر شکل دیگری از خروجی یا فیلترهای جدیدی رو مد نظر داشته باشیم، دیگه نیازی به نوشته شدن API جدید نیست، بلکه فقط کافیه تا کوئری رو تغییر بدیم.
همونقدر که انعطافپذیری ما زیاد میشه و بلافاصله میگیم دیگه تیم front-end یا mobile-app نیازی به انتظار برای نوشته و آماده شدن APIهای جدید نیست، همونقدر هم باید حواسمون باشه که:
- سنگین شدن بار پردازشی: بهخاطر اجرای کوئریهای پیچیده میتونه بار سنگینی به سرور تحمیل کنه و به دلیل پویا بودن کوئریها کنترل کردن این شرایط دشوار میشه… به روزهای خوش آزمودن GraphQL روی ماشین خودمون دل نبندیم، توی یک سازمان بزرگ گاهی راه بازگشتی نیست و برای کنترل performance هم تحت فشار قرار خواهیم گرفت
- مدیریت نرخ درخواست: بهعلت داینامیک بودن پرسشها در درخواستها.
- امنیت: مسائلی مثل حمله به دادههای بزرگ، دشواریهای کنترل سطح دسترسی افراد در کوئریهایی که کاملا پویا هم هستند، نیازمند دقت و برنامهریزی دقیق و سختگیرانهای است.
من قصد ندارم تا در یک پست وبلاگی GraphQL رو تدریس کنم، منابع کامل و دقیقی هست که در انتها درج میکنم. ترجیح میدم با یک مرور یک مثال واقعی براتون توضیح بدم:
خلاصه فنی از تجربیات Coursera با GraphQL
یکی از بزرگترین اسامی صنعت آموزش آنلاین، Coursera حدود ۸ سال پیش تصمیم گرفت از GraphQL استفاده کنه، وقتی ابتدا با استفاده از REST API شروع کرده بود (برای کار با دادههایی مثل دورهها، اساتید و نمرات) عملکرد قابل قبولی هم داشته. اما با رشد محصول، مشکلات زیر پیدا شدن:
- افزایش تعداد APIها (بیش از 1000 API)، که مدیریت و مستندسازی آنها سخت بود.
- پرفورمنس پایین: نیاز به چندین درخواست برای جمعآوری دادههای مورد نیاز برای هر صفحه.
- تجربه توسعهدهنده ضعیف: مستندسازی ناکافی و سختی در پیدا کردن دادهها.
برای حل این مشکلات، GraphQL رو به عنوان یک راهحل بالقوه بررسی کردن، اما به دلیل هزینه بالای مهاجرت کامل به GraphQL، تصمیم گرفتن یک لایهی مبتنی بر GraphQL رو روی REST APIهای موجود بسازن.
پیادهسازی اولیه
- راهاندازی GraphQL Proxy Layer:
- یک لایه، درخواستهای GraphQL رو به REST APIهای موجود ترجمه میکردن.
- این راهکار به تیمها اجازه میداد بدون تغییر در سرویسهای بکاند، از GraphQL استفاده کنن.
- مشکلات اولیه:
- رشد بیش از حد اسکیما (۷۰۰۰ تایپ)
- مشکل همگامسازی سازگاری اسکیما با سرویسهای REST عدم انعطافپذیری کافی برای نیازهای محصول
- نیاز به فرآیندی برای بهروزرسانی خودکار اسکیمای GraphQL متناسب با تغییرات REST.
راهکار
تیم Coursera متوجه میشه که رویکرد قبلیشون (Data-First Schema) با هدف اصلی GraphQL یعنی تمرکز بر نیازهای محصول در تضاد بوده، برای همین هم:
- بهروزرسانی اتوماتیک schemaها هر ۵ دقیقه
- اضافه کردن روابط بین منابع
- تمرکز بر کیفیت اسکیما به جای کمیت: محدود کردن دادههایی که وارد GraphQL میشن.
- ارتباط بهتر بین تیمها: استفاده از GraphQL به عنوان زبان مشترک برای ارتباط بین تیمهای فرانتاند و بکاند.
- حاکمیت مرکزی برای اسکیما: ایجاد فرآیندها و ابزارهایی که تغییرات اسکیما را بهتر مدیریت کنند.
این راهکارها مشکل اسکیمای GraphQL رو با همیشه بهروز نگه داشتنشون حل کرده و همراستا با معماری REST نگهداری کرده. ولی چالشهای توسعهای زیاد، و همچنین موضوعات یادگیری و نیاز تیم به مشورتگیری و تغییر رویهها رو با خودش همراه داشته.
چالشهای ارتباطی بین منابع
در ابتدا Coursera با نگهداری REST API ها در سیلوهایی جداگانه از هم به کار میبرده و ارتباطی بین آنها تعریف نشده بود. ولی توی GraphQL، ارتباط بین منابع ضروری است. برای حل این مشکل:
- یک سیستم Annotation طراحی کردن که روابط بین منابع را بهصورت Forward یا Reverse مشخص میشه.
- این روابط امکان ساخت اسکیمای یکپارچه و مرتبط را فراهم کردن.
- استفاده از نامگذاری مبتنی بر Namespace برای هماهنگی REST APIها که اصطلاحا Schema Stitching گفته میشه و با این روش مشکلات همپوشانی و ناسازگاری رو کاهش دادن، اما تغییرات در فیلدها دشوار بوده.
نتیجهگیری
درسته که تبلیغات زیادی برای GraphQL میبینیم، ولی بدون داشتن زیرساختهای فنی و فرایندی، برای محصولات بزرگ، میتونه تبدیل به کابوس شه، کابوس نگهداری schemaها، کابوس پرفرمنس، کابوس امنیت. در طرف مقابل هم، توسعه بدون مدیریت REST API میتونه منجر به معضل API Sprawl بشه، یعنی تیمها و دپارتمانهای مختلف بدون پیروی از چارچوب و قواعد و دستورالعملها، همینجوری API توسعه بدن و بعدتر کابوس API Sprawl رو به وجود بیارن.
موضوع Governance بحث مهمی توی معماری نرمافزار خصوصا در انترپرایزهاست که میشه در مورد توی پستهای جداگانهای صحبت کرد…
نظرتون رو حتمن بنویسید…
منابع برای علاقهمندها:
- یادگیری GraphQL Querying
- یک ویدیو خیلی خوب برای داتنتیها از NDC 2023
- مقاله و مثال خوب برای داتنتیها ۱ و ۲
- فهرست ابزارها و کتابخونههای مهم کار با GraphQL
- گزارش تحلیلی از وضعیت GraphQL در مارکت (۲۰۲۴)
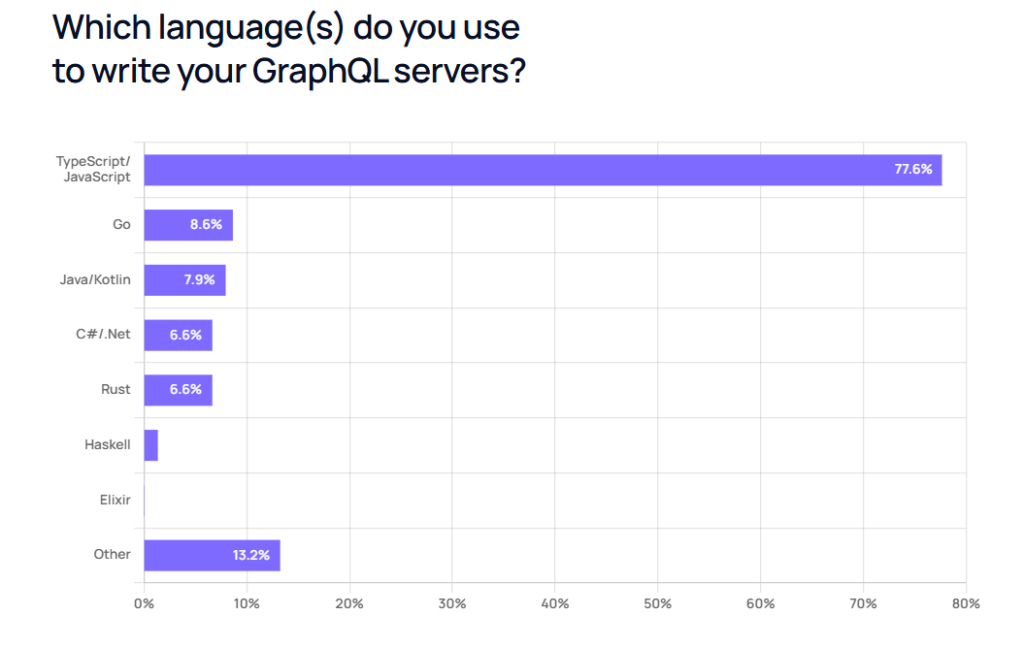
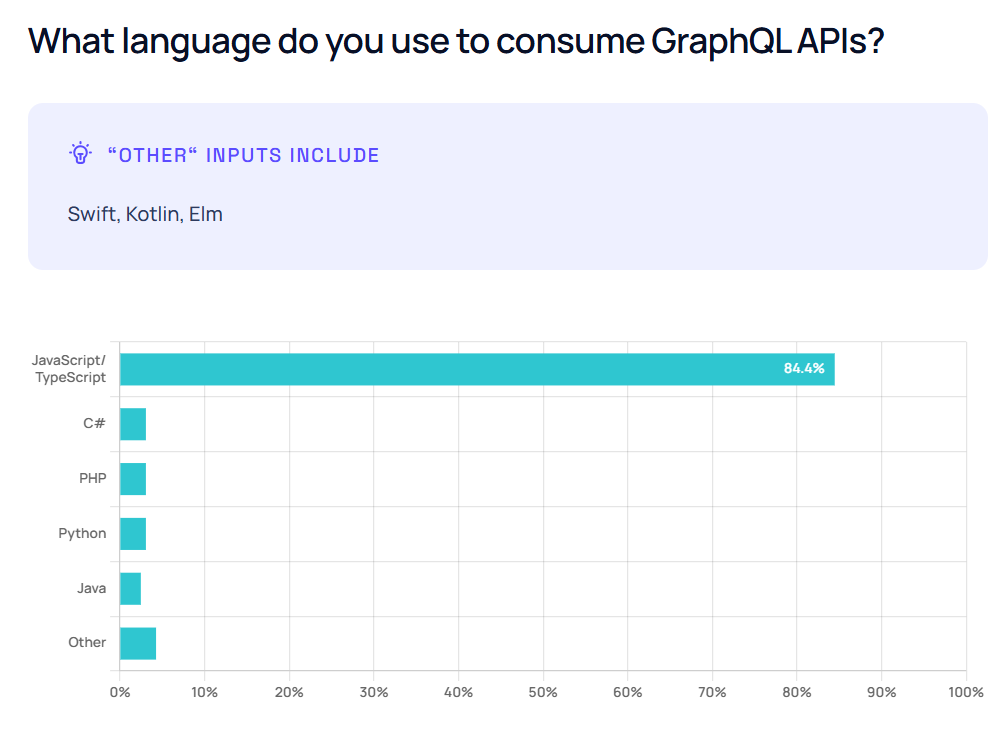
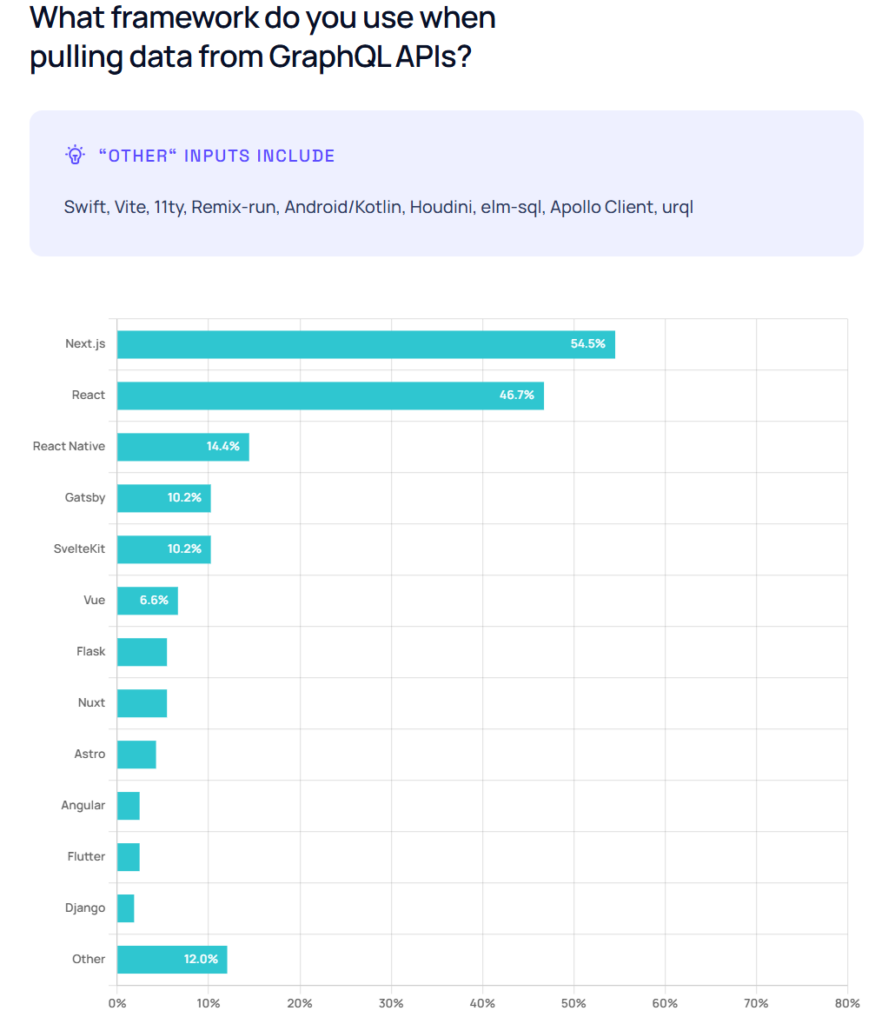
ما تو یه پروژه رفتیم سراغش
واقعا پشیمون شدیم، پیاده سازی عجیب و پیچیده و امنیت پایین، اکثرا هم جاوا کار قدیمی و باتجربه بودن