سالهاست که دیگه اکثر نرمافزارها بهصورت منفرد و مستقل کار نمیکنن. از نرمافزار کوچکی که فقط یک API پرداخت رو صدا میکنه؛ تا نرمافزارهای توزیعشده و microservice هایی که دهها یا صدها API مختلف رو دا میکنند، بالاخره این وابستگی به یک سرویس مستقل دیگه وجود داره.
حالا توی این شرایط، همیشه همه چیز طبق برنامه پیش نمیره. گاهی اوقات ممکنه درخواستهای ما به یک سرویس خارجی یا API به دلیل مشکلات موقت مثل ازدحام شبکه یا قطعیهای کوتاه مدت، شکست بخوره و نتونه پاسخ درست بگیره. اینجاست که یک راهکار مهم به نام Retry Pattern به کمک ما میآید.
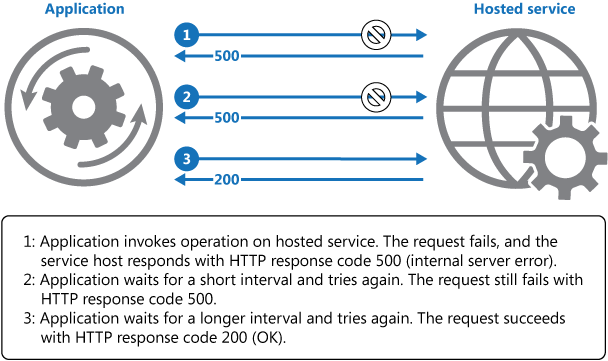
💡 الگوی Retry Pattern چیه؟ الگوی Retry Pattern یکی از الگوهای معماری در توسعه نرمافزار است که به ما اجازه میده تا در صورت بروز یک شکست موقت (Failure)، درخواست رو بهصورت خودکار، مجدداً امتحان کنیم. به جای اینکه بلافاصله شکست را قبول کنیم و کل فرایند رو با خطا به اتمام برسونیم، سیستم تلاش میکنه تا درخواست را پس از یک تأخیر کوتاه دوباره ارسال کنه. این الگو به خصوص در سرویسهای ابری که در معرض ناپایداریهای موقت هستند، بسیار مفیده.
🔧 چگونه این الگو کار میکند؟ فرض کنید اپلیکیشن شما قصد داره به یک API خارجی درخواست ارسال کنه، اما به دلیل مشکلاتی مثل قطع موقت شبکه یا محدودیت سرعت در سمت سرور، درخواست با شکست مواجه میشه. در چنین شرایطی، به جای توقف عملیات، سیستم شما میتواند بهطور خودکار درخواست را پس از یک زمانبندی خاص (مثل ۱ ثانیه، ۳ ثانیه، ۵ ثانیه) دوباره ارسال کند. این روند میتواند چندین بار تکرار شود تا زمانی که یا درخواست موفقیتآمیز باشد یا به حداکثر تعداد تلاشها برسه، حتی مثلا بعد از ۵ تلاش ناموفق، به آدرس دیگهای درخواست بفرسته (بهصورت کلی: شما دستورالعمل چگونگی مواجهه با خطا رو تعیین میکنید).
📝 یک مثال ساده: تصور کنید یک اپلیکیشن دارید که باید اطلاعات آبوهوا را از یک API دریافت کنه. در اولین تلاش، به دلیل مشکلات موقتی در سرور API، درخواست شما شکست میخوره. به جای اینکه اپلیکیشن به کاربر پیام خطا نشان بده، از الگوی Retry استفاده میکنه و پس از چند ثانیه دوباره تلاش میکند، بعد از ۳ تلاش ناموفق، ۱ درخواست به API دیگه میفرسته، و اگر اون هم جواب نداد، اون وقت به کاربر خطا نشون میدید. ولی اگر در تلاش دوم یا سوم، درخواست موفقیتآمیز باشد، کاربر هرگز متوجه شکست اولیه نمیشه و تجربه کاربری بهبود مییابد.
🔑 نکات مهم:
- حداکثر تعداد تلاشها: همیشه باید یک محدودیت برای تعداد دفعاتی که درخواست تکرار میشود تعیین کنید تا از ایجاد بار اضافی بر روی سرورهای خارجی جلوگیری شود.
- تأخیر بین تلاشها: بهتر است بین هر تلاش کمی تأخیر بگذارید و این تأخیر میتواند با هر بار تلاش بیشتر شود (مثلاً ۱ ثانیه، ۲ ثانیه، ۴ ثانیه).
- پیشبینی شکستها: این الگو فقط برای شکستهای موقت مناسب است و در مواردی که مشکل دائمی است (مثلاً آدرس API اشتباه است)، نباید استفاده شود.
- راهکار جایگزین: همیشه بدترین سناریو رو تصور کنید و ببنید آیا میشه در اون حالت هم کاری کرد که کاربر خوشحالتر باشه، سیستم پایدارتر باشه؟!
📘 برای پیادهسازی، من تجربه کتابخونههای زیر رو به فراخور پروژه و نیاز داشتم، پیشنهاد شما چیه؟
Polly برای معروفترین کتابخونه برای NET. است (مثال)
Microsoft.Extensions.Http.Resilience کتابخونه سادهتر، سبکتر از Polly برای داتنت